




As information and facts and processing requirements have developed, ache factors these types of as overall performance and resiliency have necessitated new remedies. Databases have to have to keep ACID compliance and consistency, give superior availability and superior overall performance, and tackle enormous workloads with out turning out to be a drain on sources. Sharding has available a remedy, but for a lot of firms sharding has reached its restrictions, thanks to its complexity and resource necessities. A better remedy is distributed SQL.
In a distributed SQL implementation, the database is distributed across many actual physical systems, offering transactions at a globally scalable stage. MariaDB System X5, a significant release that involves upgrades to every facet of MariaDB System, gives distributed SQL and enormous scalability by way of the addition of a new intelligent storage engine known as Xpand. With a shared very little architecture, thoroughly distributed ACID transactions, and strong consistency, Xpand allows you to scale to hundreds of thousands of transactions per 2nd.
Optimized pluggable intelligent engines
MariaDB Organization Server is architected to use pluggable storage engines (like Xpand) to enhance for certain workloads from a one platform. There is no have to have for specialized databases to tackle certain workloads. MariaDB Xpand, our intelligent engine for distributed SQL, is the most current addition to our lineup. Xpand adds massively scalable distributed transactional capabilities to the solutions supplied by our other engines. Our other pluggable engines give optimization for analytical (columnar), browse-significant workloads, and publish-significant workloads. You can blend and match replicated, distributed, and columnar tables to enhance every database for your certain necessities.
Including MariaDB Xpand enables enterprise shoppers to achieve all the positive aspects of distributed SQL – velocity, availability, and scalability – even though retaining the MariaDB positive aspects they are accustomed to.
Let us consider a superior-stage look at how MariaDB Xpand gives distributed SQL.
Distributed SQL down to the indexes
Xpand gives distributed SQL by slicing, replicating, and distributing data across nodes. What does this indicate? We’ll use a extremely easy instance with a single table and a few nodes to demonstrate the concepts. Not revealed in this instance is that all slices are replicated.
 MariaDB
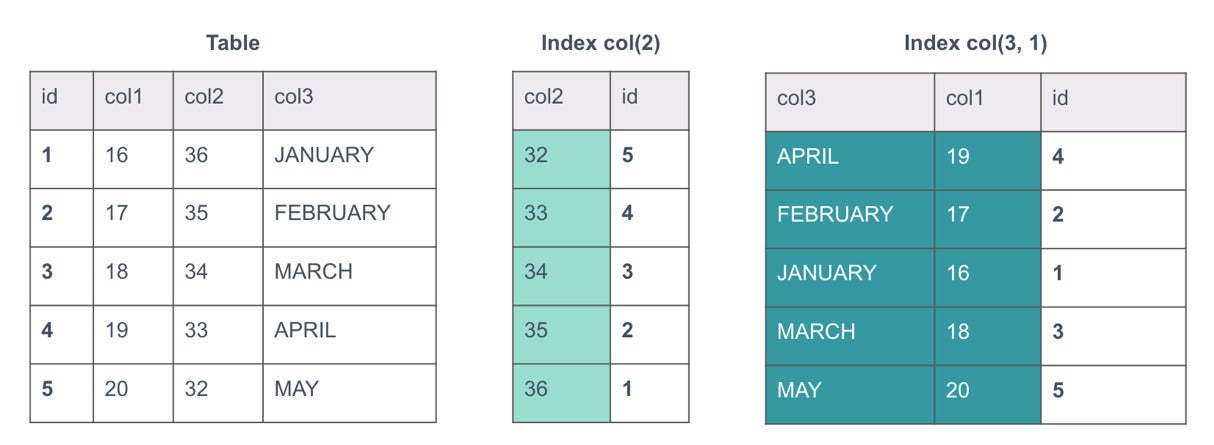
MariaDBDetermine 1. Sample table with indexes
In Determine 1 previously mentioned, we have a table with two indexes. The table has some dates and we have an index on column two, and a further on columns three and 1. Indexes are in a sense tables themselves. They’re subsets of the table. The major essential is id, the initial index in the table. That is what will be utilized to hash and distribute the table data out all-around the database.
 MariaDB
MariaDBDetermine two. Xpand slices and distributes data, such as indexes, across nodes. (Replication is not revealed for good reasons of simplicity. All slices have at minimum two replicas.)
Now we add the notion of slices. Slices are basically horizontal partitions of the table. We have 5 rows in our table. In Determine two, the table has been sliced and distributed. Node #1 has two rows. Node #two has two rows, and Node #three has a single row. The objective is to have the data distributed as evenly as achievable across the nodes.
The indexes have also been sliced and distributed. This is a essential difference involving Xpand and other distributed remedies. Usually, distributed databases have community indexes, so every node has an index of its very own data. In Xpand, indexes are distributed and saved independently of the table. This eradicates the have to have to send out a query to all nodes (scatter/get). In the instance previously mentioned, Node #1 contains rows two and 4 of the table, and also contains indexes for rows 32 and 35 and rows April and March. The table and the indexes are independently sliced, distributed, and replicated across the nodes.
The query engine employs the distributed indexes to identify the place to uncover the data. It seems to be up only the index partitions necessary and then sends queries only to the destinations the place the necessary data reside. Queries are all distributed. They’re performed concurrently and in parallel. In which they go is dependent completely on the data and what is necessary to take care of the query.
All slices are replicated at minimum 2 times. For every slice, there are replicas residing on other nodes. By default, there will be a few copies of that data – the slice and two replicas. Every single copy will be on a different node, and if you ended up managing in many availability zones, all those copies would also be sitting in different availability zones.
Browse and publish managing
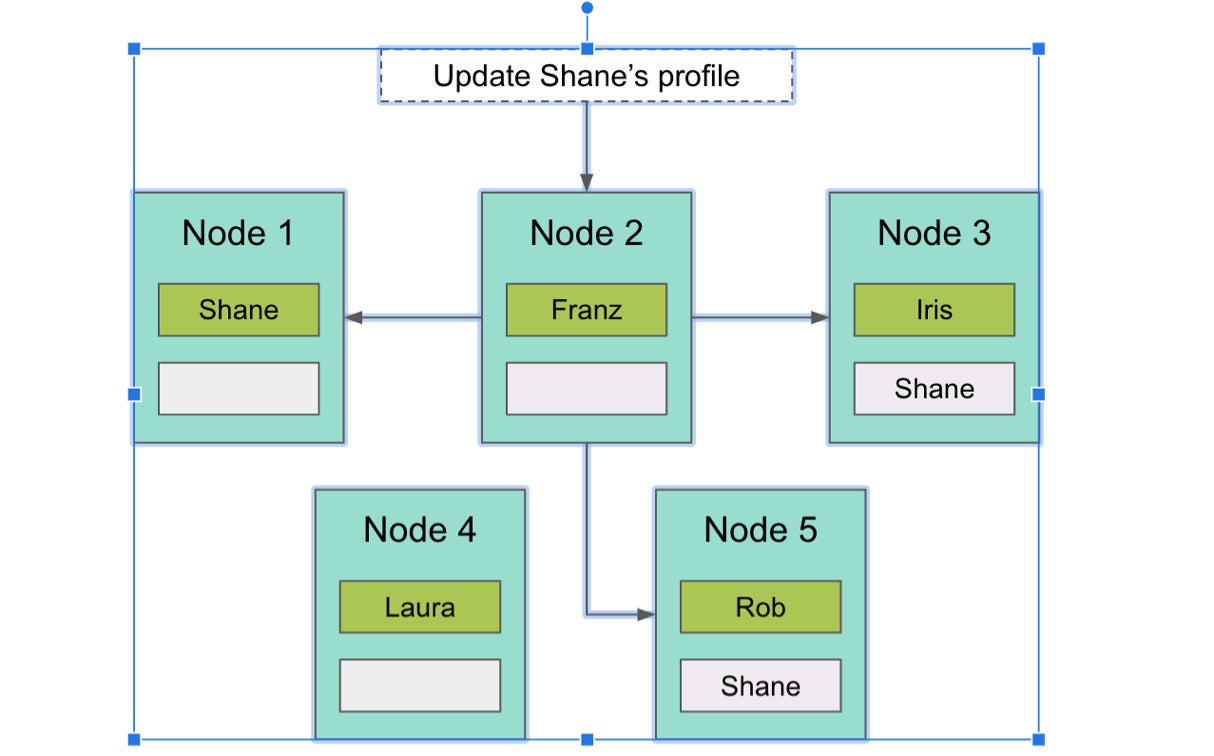
Let us consider a further instance. In Determine three, we have 5 scenarios of MariaDB Organization Server with Xpand (nodes). There’s a table to retail store consumer profiles. The slice with Shane’s profile is on Node #1 with copies on Node #three and Node #5. Queries can arrive in on any node and will be processed in different ways relying on if they are reads or writes.
 MariaDB
MariaDBDetermine three. Writes are processed at the same time to all copies in a distributed transaction.
Writes are created to all copies synchronously inside of a distributed transaction. Any time I update my “Shane” profile for the reason that I altered my email or I altered my address, all those writes go to all copies at the exact same time inside a transaction. This is what gives strong consistency.
In Determine three, the UPDATE assertion went to Node #two. There is very little on Node #two regarding my profile but Node #two is aware the place my profile is and sends updates to Node #1, Node #three, and Node #5, then commits that transaction and returns back to the application.
Reads are taken care of in different ways. In the diagram, the slice with my profile on it is on Node #1 with copies on Node #three and Node #5. This makes Node #1 the rating replica. Just about every slice has a rating replica, which could be stated to be the node that “owns” the data. By default, no matter which node a browse comes in on, it constantly goes to the rating replica, so every Select that resolves to me will go to Node #1.
Giving elasticity
Distributed databases like Xpand are constantly shifting and evolving relying on the data in the application. The rebalancer course of action is accountable for adapting the data distribution to existing requirements and retaining the exceptional distribution of slices across nodes. There are a few common situations that phone for redistribution: incorporating nodes, removing nodes, and preventing uneven workloads or “hot spots.”
For instance, say we are managing with a few nodes but uncover traffic is escalating and we have to have to scale – we add a fourth node to tackle the traffic. Node #4 is vacant when we add it as revealed in Determine 4. The rebalancer automatically moves slices and replicas to make use of Node #4, as revealed in Determine 5.
 MariaDB
MariaDBDetermine 4. Node 4 has been included to tackle amplified traffic. Nodes are vacant when they are included to the Xpand cluster.
 MariaDB
MariaDBDetermine 5. The Xpand rebalancer redistributes slices and replicas to consider gain of the amplified capacity.
If Node #4 should really fall short, the rebalancer automatically goes to perform again this time recreating slices from their replicas. No data is misplaced. Replicas are also recreated to replace all those that ended up residing on Node #4, so all slices again have replicas on other nodes to ensure superior availability.
 MariaDB
MariaDBDetermine six. If a node fails, the Xpand rebalancer recreates the slices and the replicas that resided on the failed node from the replica data on the other nodes.
Balancing the workload
In addition to scale out and superior availability, the rebalancer mitigates unequal workload distribution – both incredibly hot spots or underutilization. Even when data is randomly distributed with a perfect hash algorithm, incredibly hot spots can occur. For instance, it could transpire just by chance that the 10 items on sale this thirty day period transpire to be sitting on Node #1. The data is evenly distributed but the workload is not (Determine seven). In this variety of state of affairs, the rebalancer will redistribute slices to balance resource utilization (Determine eight).
 MariaDB
MariaDBDetermine seven. Xpand has evenly distributed the data but the workload is uneven. Node 1 has a significantly bigger workload than the other a few nodes.
 MariaDB
MariaDBDetermine eight. Xpand’s rebalancer redistributes data slices to balance the workload across nodes.
Scalability, velocity, availability, balance
Details and processing requirements will go on to improve. That is a provided. MariaDB Xpand gives a consistent, ACID-compliant scaling remedy for enterprises with necessities that can not be met with other alternatives like replication and sharding.
Distributed SQL gives scalability, and MariaDB Xpand gives the overall flexibility to pick out how much scalability you have to have. Distribute a single table or many tables or even your entire database, the decision is yours. Operationally, capacity is very easily adjusted to meet shifting workload needs at any provided time. You by no means have to be around-provisioned.
Xpand also transparently safeguards towards uneven resource utilization, dynamically redistributing data to balance the workload across nodes and protect against incredibly hot spots. For builders, there is no have to have to be concerned about scalability and overall performance. Xpand is elastic. Xpand also gives redundancy and superior availability. With data sliced, replicated, and distributed across nodes, data is guarded and redundancy is maintained in the function of components failure.
And, with MariaDB’s architecture, your distributed tables will engage in nicely – such as cross-engine JOINs – with your other MariaDB tables. Make the database remedy you have to have by mixing and matching replicated, distributed, or columnar tables all on a one database on MariaDB System.
Shane Johnson is senior director of products internet marketing at MariaDB Corporation. Prior to MariaDB, he led products and complex internet marketing at Couchbase. In the previous, he carried out complex roles in growth, architecture, and evangelism at Pink Hat and other firms. His background is in Java and distributed systems.
—
New Tech Forum gives a venue to take a look at and go over rising enterprise technologies in unprecedented depth and breadth. The choice is subjective, centered on our decide of the technologies we consider to be important and of finest curiosity to InfoWorld readers. InfoWorld does not accept internet marketing collateral for publication and reserves the proper to edit all contributed information. Send out all inquiries to [email protected].
Copyright © 2020 IDG Communications, Inc.
More Stories
Automatic Cooking Machine, Commercial Kitchen Equipment, Meat Stewing Machine
What is Intellectual Property and 3 Key Issues About It
Snapshot: The Wacky History Behind 3D Television Technology