




Whilst device finding out has been all-around a very long time, deep learning has taken on a everyday living of its own recently. The rationale for that has largely to do with the raising quantities of computing power that have become greatly available—along with the burgeoning quantities of data that can be conveniently harvested and made use of to prepare neural networks.
The volume of computing energy at people’s fingertips started out escalating in leaps and bounds at the change of the millennium, when graphical processing models (GPUs) started to be
harnessed for nongraphical calculations, a craze that has develop into increasingly pervasive about the earlier 10 years. But the computing demands of deep understanding have been rising even speedier. This dynamic has spurred engineers to create electronic hardware accelerators particularly focused to deep understanding, Google’s Tensor Processing Device (TPU) staying a key case in point.
Here, I will describe a incredibly different tactic to this problem—using optical processors to have out neural-network calculations with photons instead of electrons. To fully grasp how optics can serve here, you want to know a small little bit about how computer systems at this time carry out neural-community calculations. So bear with me as I define what goes on under the hood.
Virtually invariably, artificial neurons are constructed utilizing special computer software jogging on digital electronic desktops of some type. That software supplies a supplied neuron with numerous inputs and one particular output. The condition of just about every neuron relies upon on the weighted sum of its inputs, to which a nonlinear functionality, named an activation purpose, is utilized. The end result, the output of this neuron, then gets an enter for various other neurons.
Cutting down the power desires of neural networks could need computing with gentle
For computational effectiveness, these neurons are grouped into layers, with neurons related only to neurons in adjacent layers. The advantage of arranging items that way, as opposed to letting connections involving any two neurons, is that it will allow specified mathematical tips of linear algebra to be utilised to pace the calculations.
Whilst they are not the full story, these linear-algebra calculations are the most computationally demanding element of deep discovering, significantly as the dimension of the community grows. This is correct for both of those schooling (the system of figuring out what weights to apply to the inputs for each individual neuron) and for inference (when the neural network is providing the wished-for benefits).
What are these mysterious linear-algebra calculations? They aren’t so sophisticated actually. They include operations on
matrices, which are just rectangular arrays of numbers—spreadsheets if you will, minus the descriptive column headers you may possibly find in a typical Excel file.
This is great news mainly because fashionable laptop components has been very nicely optimized for matrix functions, which ended up the bread and butter of significant-overall performance computing long prior to deep finding out turned common. The appropriate matrix calculations for deep finding out boil down to a significant variety of multiply-and-accumulate operations, whereby pairs of figures are multiplied jointly and their products and solutions are extra up.
Above the a long time, deep learning has necessary an ever-growing quantity of these multiply-and-accumulate functions. Take into account
LeNet, a groundbreaking deep neural community, designed to do image classification. In 1998 it was demonstrated to outperform other equipment strategies for recognizing handwritten letters and numerals. But by 2012 AlexNet, a neural network that crunched by about 1,600 situations as several multiply-and-accumulate functions as LeNet, was in a position to acknowledge hundreds of unique types of objects in pictures.
Advancing from LeNet’s first achievements to AlexNet demanded practically 11 doublings of computing functionality. For the duration of the 14 years that took, Moore’s legislation offered a lot of that maximize. The problem has been to retain this pattern heading now that Moore’s legislation is functioning out of steam. The typical resolution is only to throw more computing resources—along with time, money, and energy—at the difficulty.
As a result, education today’s large neural networks typically has a major environmental footprint. 1
2019 analyze discovered, for instance, that schooling a certain deep neural network for natural-language processing created 5 instances the CO2 emissions normally involved with driving an auto over its lifetime.
Improvements in digital electronic computer systems authorized deep finding out to blossom, to be confident. But that won’t suggest that the only way to carry out neural-network calculations is with this sort of machines. A long time in the past, when digital pcs were being still somewhat primitive, some engineers tackled tricky calculations working with analog pcs in its place. As electronic electronics enhanced, all those analog pcs fell by the wayside. But it could be time to go after that approach after again, in particular when the analog computations can be carried out optically.
It has prolonged been known that optical fibers can help a great deal better facts fees than electrical wires. That’s why all lengthy-haul communication lines went optical, starting off in the late 1970s. Due to the fact then, optical data inbound links have replaced copper wires for shorter and shorter spans, all the way down to rack-to-rack interaction in information centers. Optical information interaction is quicker and uses a lot less electricity. Optical computing guarantees the exact same positive aspects.
But there is a major variation in between communicating facts and computing with it. And this is where by analog optical approaches strike a roadblock. Traditional computer systems are primarily based on transistors, which are remarkably nonlinear circuit elements—meaning that their outputs aren’t just proportional to their inputs, at least when applied for computing. Nonlinearity is what lets transistors swap on and off, permitting them to be fashioned into logic gates. This switching is simple to attain with electronics, for which nonlinearities are a dime a dozen. But photons abide by Maxwell’s equations, which are annoyingly linear, meaning that the output of an optical device is typically proportional to its inputs.
The trick is to use the linearity of optical products to do the a person issue that deep learning depends on most: linear algebra.
To illustrate how that can be done, I’ll describe right here a photonic unit that, when coupled to some straightforward analog electronics, can multiply two matrices with each other. These multiplication combines the rows of 1 matrix with the columns of the other. A lot more specifically, it multiplies pairs of numbers from these rows and columns and provides their merchandise together—the multiply-and-accumulate operations I described earlier. My MIT colleagues and I revealed a paper about how this could be carried out
in 2019. We are functioning now to build this sort of an optical matrix multiplier.
Optical facts communication is more rapidly and makes use of much less electricity. Optical computing claims the very same benefits.
The basic computing unit in this machine is an optical element named a
beam splitter. Even though its make-up is in truth a lot more complex, you can assume of it as a fifty percent-silvered mirror established at a 45-degree angle. If you send a beam of mild into it from the facet, the beam splitter will enable fifty percent that gentle to pass straight through it, while the other 50 % is mirrored from the angled mirror, causing it to bounce off at 90 degrees from the incoming beam.
Now glow a 2nd beam of gentle, perpendicular to the initial, into this beam splitter so that it impinges on the other aspect of the angled mirror. Half of this second beam will likewise be transmitted and fifty percent mirrored at 90 levels. The two output beams will mix with the two outputs from the very first beam. So this beam splitter has two inputs and two outputs.
To use this machine for matrix multiplication, you crank out two light beams with electric powered-subject intensities that are proportional to the two quantities you want to multiply. Let’s phone these discipline intensities
x and y. Shine individuals two beams into the beam splitter, which will merge these two beams. This certain beam splitter does that in a way that will create two outputs whose electrical fields have values of (x + y)/√2 and (x − y)/√2.
In addition to the beam splitter, this analog multiplier necessitates two very simple digital components—photodetectors—to measure the two output beams. They don’t evaluate the electrical area depth of these beams, although. They evaluate the power of a beam, which is proportional to the sq. of its electrical-industry intensity.
Why is that relation critical? To fully grasp that calls for some algebra—but nothing at all outside of what you figured out in large college. Remember that when you sq. (
x + y)/√2 you get (x2 + 2xy + y2)/2. And when you sq. (x − y)/√2, you get (x2 − 2xy + y2)/2. Subtracting the latter from the former provides 2xy.
Pause now to contemplate the importance of this very simple little bit of math. It indicates that if you encode a variety as a beam of gentle of a particular depth and an additional amount as a beam of yet another depth, ship them as a result of such a beam splitter, evaluate the two outputs with photodetectors, and negate just one of the resulting electrical indicators right before summing them collectively, you will have a signal proportional to the product of your two figures.
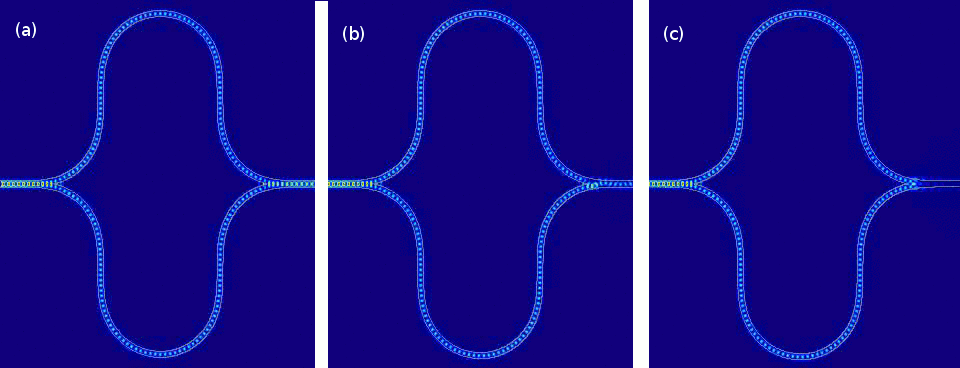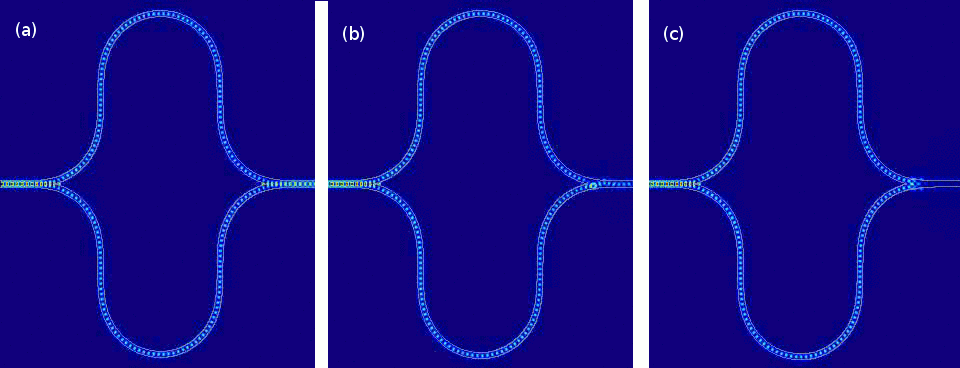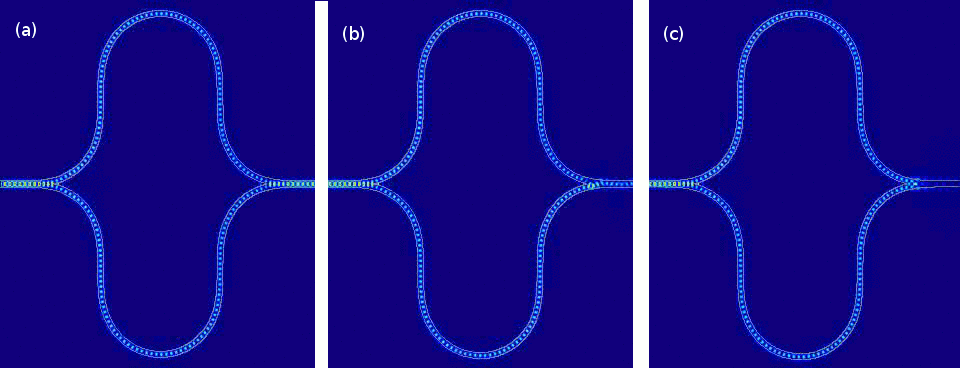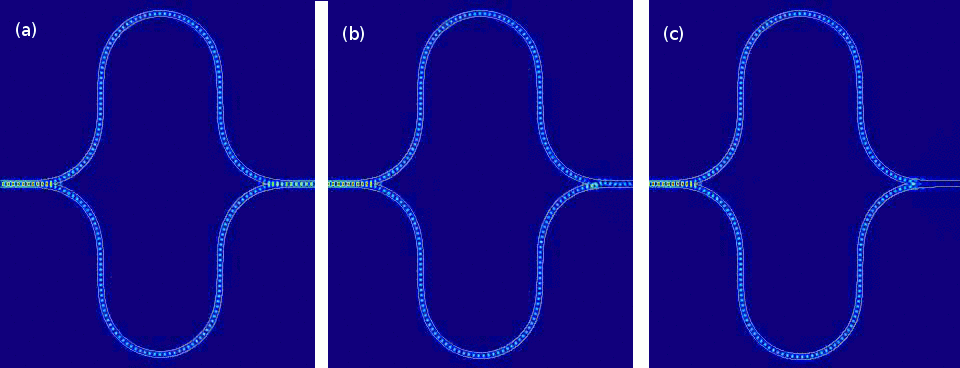
Simulations of the built-in Mach-Zehnder interferometer found in Lightmatter’s neural-community accelerator present 3 different disorders whereby light traveling in the two branches of the interferometer undergoes diverse relative stage shifts ( degrees in a, 45 degrees in b, and 90 degrees in c).
Lightmatter
My description has designed it sound as while every single of these gentle beams will have to be held constant. In fact, you can briefly pulse the light in the two input beams and measure the output pulse. Much better nonetheless, you can feed the output sign into a capacitor, which will then accumulate demand for as extensive as the pulse lasts. Then you can pulse the inputs all over again for the exact length, this time encoding two new quantities to be multiplied collectively. Their product adds some far more cost to the capacitor. You can repeat this system as lots of times as you like, each individual time carrying out a different multiply-and-accumulate operation.
Using pulsed light-weight in this way makes it possible for you to carry out several these types of operations in quick-fire sequence. The most energy-intense aspect of all this is examining the voltage on that capacitor, which needs an analog-to-electronic converter. But you do not have to do that after every pulse—you can wait until finally the conclusion of a sequence of, say,
N pulses. That means that the unit can carry out N multiply-and-accumulate operations making use of the similar volume of electricity to read through the response no matter whether N is compact or massive. Here, N corresponds to the range of neurons per layer in your neural network, which can easily range in the hundreds. So this tactic works by using pretty minimal energy.
Occasionally you can save electrical power on the input facet of items, much too. That is due to the fact the same benefit is generally utilized as an input to multiple neurons. Fairly than that range being transformed into mild multiple times—consuming strength just about every time—it can be transformed just once, and the light-weight beam that is made can be break up into a lot of channels. In this way, the vitality price of input conversion is amortized over quite a few functions.
Splitting just one beam into a lot of channels necessitates very little extra complex than a lens, but lenses can be tricky to put on to a chip. So the unit we are creating to complete neural-community calculations optically may well well end up becoming a hybrid that brings together really integrated photonic chips with separate optical components.
I’ve outlined here the system my colleagues and I have been pursuing, but there are other strategies to skin an optical cat. A different promising scheme is centered on something referred to as a Mach-Zehnder interferometer, which brings together two beam splitters and two fully reflecting mirrors. It, way too, can be utilised to carry out matrix multiplication optically. Two MIT-centered startups, Lightmatter and Lightelligence, are acquiring optical neural-community accelerators primarily based on this approach. Lightmatter has now developed a prototype that works by using an optical chip it has fabricated. And the business expects to get started selling an optical accelerator board that works by using that chip afterwards this 12 months.
Yet another startup applying optics for computing is
Optalysis, which hopes to revive a somewhat old thought. One of the 1st utilizes of optical computing back again in the 1960s was for the processing of synthetic-aperture radar information. A vital component of the challenge was to utilize to the measured knowledge a mathematical procedure termed the Fourier completely transform. Digital personal computers of the time struggled with such issues. Even now, implementing the Fourier change to substantial amounts of info can be computationally intensive. But a Fourier remodel can be carried out optically with absolutely nothing a lot more sophisticated than a lens, which for some years was how engineers processed artificial-aperture knowledge. Optalysis hopes to deliver this strategy up to day and apply it much more extensively.
Theoretically, photonics has the prospective to accelerate deep mastering by several orders of magnitude.
There is also a business known as
Luminous, spun out of Princeton University, which is working to develop spiking neural networks based mostly on one thing it calls a laser neuron. Spiking neural networks more carefully mimic how organic neural networks perform and, like our personal brains, are able to compute employing incredibly very little power. Luminous’s hardware is still in the early section of growth, but the guarantee of combining two electricity-conserving approaches—spiking and optics—is fairly thrilling.
There are, of training course, continue to many specialized difficulties to be prevail over. A single is to strengthen the accuracy and dynamic selection of the analog optical calculations, which are nowhere in the vicinity of as great as what can be realized with digital electronics. That is for the reason that these optical processors undergo from several sources of sound and mainly because the digital-to-analog and analog-to-digital converters utilized to get the details in and out are of confined precision. In truth, it really is tricky to imagine an optical neural community functioning with far more than 8 to 10 bits of precision. When 8-bit electronic deep-studying hardware exists (the Google TPU is a excellent example), this marketplace demands increased precision, especially for neural-network training.
There is also the difficulty integrating optical elements onto a chip. Due to the fact people components are tens of micrometers in size, they are unable to be packed practically as tightly as transistors, so the necessary chip region provides up swiftly.
A 2017 demonstration of this method by MIT researchers concerned a chip that was 1.5 millimeters on a side. Even the most significant chips are no greater than a number of sq. centimeters, which places boundaries on the measurements of matrices that can be processed in parallel this way.
There are a lot of added questions on the laptop-architecture aspect that photonics researchers are likely to sweep beneath the rug. What’s apparent however is that, at the very least theoretically, photonics has the potential to speed up deep learning by numerous orders of magnitude.
Dependent on the technology that is at present readily available for the several elements (optical modulators, detectors, amplifiers, analog-to-digital converters), it truly is fair to believe that the vitality efficiency of neural-network calculations could be built 1,000 situations superior than present-day electronic processors. Building extra intense assumptions about emerging optical technology, that aspect could possibly be as significant as a million. And since electronic processors are electricity-limited, these improvements in electrical power efficiency will probable translate into corresponding advancements in speed.
Numerous of the ideas in analog optical computing are many years outdated. Some even predate silicon computers. Schemes for optical matrix multiplication, and
even for optical neural networks, ended up first demonstrated in the 1970s. But this technique did not capture on. Will this time be distinctive? Perhaps, for 3 reasons.
Initial, deep studying is genuinely practical now, not just an academic curiosity. Next,
we can’t rely on Moore’s Law by yourself to proceed bettering electronics. And last but not least, we have a new technologies that was not accessible to earlier generations: built-in photonics. These things advise that optical neural networks will get there for authentic this time—and the upcoming of these kinds of computations might without a doubt be photonic.
More Stories
Buying iPad Accessories From Online iPad Forums
An Overview of Modern Technology
Video Doorbells – Now You’ll Know Who’s There