




Counting by various groups — at times named crosstab stories — can be a beneficial way to look at information ranging from community viewpoint surveys to healthcare assessments. For illustration, how did men and women vote by gender and age team? How quite a few software program developers who use equally R and Python are males vs. females?
There are a lot of ways to do this variety of counting by classes in R. Here, I’d like to share some of my favorites.
For the demos in this write-up, I’ll use a subset of the Stack Overflow Developers survey, which surveys developers on dozens of matters ranging from salaries to systems made use of. I’ll whittle it down with columns for languages made use of, gender, and if they code as a interest. I also additional my very own LanguageGroup column for irrespective of whether a developer described employing R, Python, equally, or neither.
If you’d like to stick to along, the final site of this write-up has directions on how to obtain and wrangle the information to get the similar information established I’m employing.
The information has one particular row for just about every survey reaction, and the 4 columns are all figures.
str(mydata) 'data.frame':83379 obs. of 4 variables: $ Gender : chr "Gentleman" "Gentleman" "Gentleman" "Gentleman" ... $ LanguageWorkedWith: chr "HTML/CSSJavaJavaScriptPython" "C++HTML/CSSPython" "HTML/CSS" "CC++C#PythonSQL" ... $ Hobbyist : chr "Of course" "No" "Of course" "No" ... $ LanguageGroup : chr "Python" "Python" "Neither" "Python" ...
I filtered the raw information to make the crosstabs much more manageable, including eliminating lacking values and taking the two most significant genders only, Gentleman and Girl.
The janitor bundle
So, what is the gender breakdown inside just about every language team? For this kind of reporting in a information frame, one particular of my go-to equipment is the janitor package’s tabyl() operate.
The simple tabyl() operate returns a information frame with counts. The very first column name you include to a tabyl() argument results in being the row, and the second one particular the column.
library(janitor) tabyl(mydata, Gender, LanguageGroup)
Gender Both Neither Python R Gentleman 3264 43908 29044 969 Girl 374 3705 1940 175
What is pleasant about tabyl() is it’s very effortless to make percents, far too. If you want to see percents for just about every column instead of raw totals, include adorn_percentages("col"). You can then pipe these results into a formatting operate these as adorn_pct_formatting().
tabyl(mydata, Gender, LanguageGroup) %>%
adorn_percentages("col") %>%
adorn_pct_formatting(digits = one)Gender Both Neither Python R Gentleman 89.7% ninety two.two% 93.7% eighty four.7% Girl ten.three% 7.8% six.three% fifteen.three%
To see percents by row, include adorn_percentages("row").
If you want to include a third variable, these as Hobbyist, that’s effortless far too.
tabyl(mydata, Gender, LanguageGroup, Hobbyist) %>%
adorn_percentages("col") %>%
adorn_pct_formatting(digits = one)
Nonetheless, it receives a little harder to visually evaluate results in much more than two concentrations this way. This code returns a checklist with one particular information frame for just about every third-degree option:
$No
Gender Both Neither Python R
Gentleman seventy nine.six% 86.7% 86.4% seventy four.six%
Girl twenty.4% thirteen.three% thirteen.six% twenty five.4%
$Of course
Gender Both Neither Python R
Gentleman ninety one.six% 93.nine% 95.% 88.%
Girl 8.4% six.one% 5.% 12.%
The CGPfunctions bundle
The CGPfunctions bundle is value a look for some brief and effortless ways to visualize crosstab information. Put in it from CRAN with the regular install.offers("CGPfunctions").
The bundle has two features of fascination for examining crosstabs: PlotXTabs() and PlotXTabs2(). This code returns bar graphs of the information (very first graph under):
library(CGPfunctions)
PlotXTabs(mydata)
 Screen shot by Sharon Machlis, IDG
Screen shot by Sharon Machlis, IDGOutcome of PlotXTabs(mydata).
PlotXTabs2(mydata) generates a graph with a different look, and some statistical summaries (2nd graph at left).
If you really do not need or want these summaries, you can eliminate them with results.subtitle = Bogus, these as PlotXTabs2(mydata, LanguageGroup, Gender, results.subtitle = Bogus).
 Screen shot by Sharon Machlis, IDG
Screen shot by Sharon Machlis, IDGOutcome of PlotXTabs(mydata).
PlotXTabs2() has a couple of dozen argument solutions, including title, caption, legends, color scheme, and one particular of 4 plot types: aspect, stack, mosaic, or per cent. There are also solutions common to ggplot2 customers, these as ggtheme and palette. You can see much more particulars in the function’s assist file.
The vtree bundle
The vtree bundle generates graphics for crosstabs as opposed to graphs. Running the key vtree() operate on one particular variable, these as
library(vtree)
vtree(mydata, "LanguageGroup")
receives you this simple reaction:
 Sharon Machlis, IDG
Sharon Machlis, IDGPrimary vtree() operate on one particular variable.
I’m not eager on the color defaults below, but you can swap in an RColorBrewer palette. vtree’s palette argument works by using palette figures, not names you can see how they’re numbered in the vtree bundle documentation. I could decide on three for Greens and 5 for Purples, for illustration. However, these defaults give you a much more intense color for decrease depend figures, which does not often make sense (and does not operate nicely for me in this illustration). I can change that default behavior with sortfill = True to use the much more intense color for the increased price.
vtree(mydata, "LanguageGroup", palette = three, sortfill = True)
 Sharon Machlis, IDG
Sharon Machlis, IDGvtree() immediately after modifying to a new palette.
If you obtain the dark color helps make it challenging to browse text, there are some solutions. 1 choice is to use the basic argument, these as vtree(mydata, "LanguageGroup", basic = True). Another choice is to established a solitary fill color instead of a palette, employing the fillcolor argument, these as vtree(mydata, LanguageGroup", fillcolor = "#99d8c9").
To look at two variables in a crosstab report, only include a 2nd column name and palette or color if you really do not want the default. You can use the basic choice or specify two palettes or two hues. Below I chose precise hues instead of palettes, and I also rotated the graph to browse vertically.
vtree(mydata, c("LanguageGroup", "Gender"),
fillcolor = c( LanguageGroup = "#e7d4e8", Gender = "#99d8c9"),
horiz = Bogus)
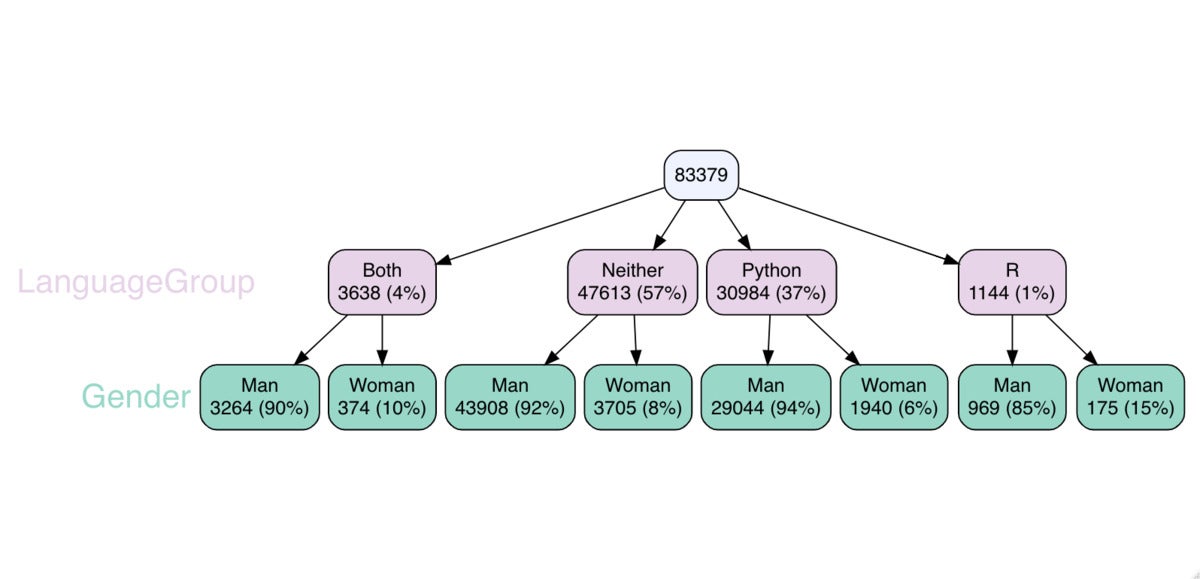 Sharon Machlis, IDG
Sharon Machlis, IDGvtree() for two variables.
You can include much more than two classes, although it receives a little bit harder to browse and stick to as the tree grows. If you are only intrigued in some of the branches, you can specify which to display with the maintain argument. Below, I established vtree() to clearly show only men and women who use R with no Python or who use equally R and Python.
vtree(mydata, c("Gender", "LanguageGroup", "Hobbyist"),
horiz = Bogus, fillcolor = c(LanguageGroup = "#e7d4e8",
Gender = "#99d8c9", Hobbyist = "#9ecae1"),
maintain = checklist(LanguageGroup = c("R", "Both")), showcount = Bogus)
With the tree receiving so hectic, I consider it assists to have possibly the depend or the per cent as node labels, not equally. So that final argument in the code higher than, showcount = Bogus, sets the graph to display only percents and not counts.
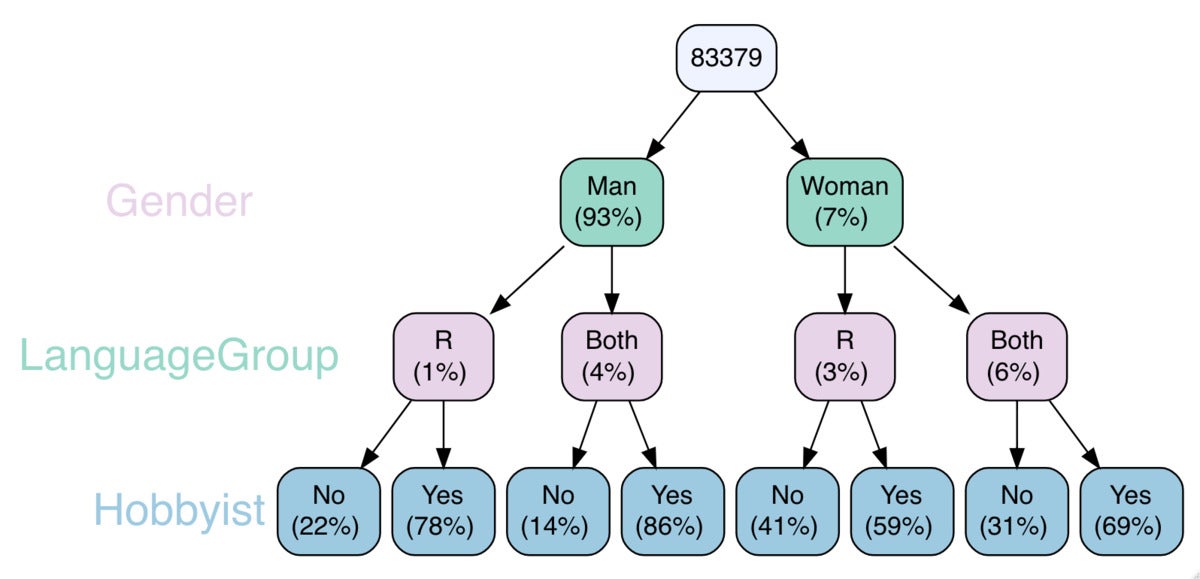 Sharon Machlis, IDG
Sharon Machlis, IDGA few-degree vtree graphic with a subset of nodes, displaying percents only.
Far more depend by team solutions
There are other beneficial ways to team and depend in R, including foundation R, dplyr, and information.desk. Foundation R has the xtabs() operate precisely for this activity. Be aware the system syntax under: a tilde and then one particular variable furthermore yet another variable.
xtabs(~ LanguageGroup + Gender, information = mydata)
Gender LanguageGroup Gentleman Girl Both 3264 374 Neither 43908 3705 Python 29044 1940 R 969 175
dplyr’s depend() operate brings together “group by” and “count rows in just about every group” into a solitary operate.
library(dplyr)
my_summary <- mydata %>%
depend(LanguageGroup, Gender, Hobbyist, type = True)my_summary LanguageGroup Gender Hobbyist n one Neither Gentleman Of course 34419 two Python Gentleman Of course 25093 three Neither Gentleman No 9489 4 Python Gentleman No 3951 5 Both Gentleman Of course 2807 six Neither Girl Of course 2250 7 Neither Girl No 1455 8 Python Girl Of course 1317 nine R Gentleman Of course 757 ten Python Girl No 623 eleven Both Gentleman No 457 12 Both Girl Of course 257 thirteen R Gentleman No 212 14 Both Girl No 117 fifteen R Girl Of course 103 sixteen R Girl No 72
In the 3 lines of code under, I load the information.desk bundle, generate a information.desk from my information, and then use the unique .N information.desk image that stands for amount of rows in a team.
library(information.desk)
mydt <- setDT(mydata)
mydt[, .N, by = .(LanguageGroup, Gender, Hobbyist)]
Visualizing with ggplot2
As with most information, ggplot2 is a great option to visualize summarized results. The very first ggplot graph under plots LanguageGroup on the X axis and the depend for just about every on the Y axis. Fill color signifies irrespective of whether a person states they code as a interest. And, aspect_wrap states: Make a individual graph for just about every price in the Gender column.
library(ggplot2)
ggplot(my_summary, aes(LanguageGroup, n, fill = Hobbyist)) +
geom_bar(stat = "identification") +
aspect_wrap(aspects = vars(Gender))
 Sharon Machlis, IDG
Sharon Machlis, IDGUtilizing ggplot2 to evaluate language use by gender.
Because there are comparatively couple females in the sample, it’s complicated to evaluate percentages across genders when equally graphs use the similar Y-axis scale. I can change that, while, so just about every graph works by using a individual scale, by introducing the argument scales = “free_y” to the aspect_wrap() operate:
ggplot(my_summary, aes(LanguageGroup, n, fill = Hobbyist)) +
geom_bar(stat = "identification") +
aspect_wrap(aspects = vars(Gender), scales = "no cost_y")
Now it’s much easier to evaluate various variables by gender.
For much more R ideas, head to the “Do Far more With R” site on InfoWorld or look at out the “Do Far more With R” YouTube playlist.
See the following site for info on how to obtain and wrangle information made use of in this demo.
More Stories
Are You Aware of the Latest Tech News?
Top 7 Questions To Ask Your Computer Repair Service Provider
How To Fix Msxml3 DLL Errors On Windows